原文链接:https://hpc.llnl.gov/tuts/openMP/
1、摘要
OpenMP 是一个应用程序接口(API),由一组主要的计算机硬件和软件供应商联合定义。OpenMP 为共享内存并行应用程序的开发人员提供了一个可移植的、可伸缩的模型。该API在多种体系结构上支持 C/C++ 和 Fortran。本教程涵盖了 OpenMP 3.1 的大部分主要特性,包括用于指定并行区域、工作共享、同步和数据环境的各种构造和指令。还将讨论运行时库函数和环境变量。本教程包括 C 和 Fortran 示例代码以及一个实验练习。
水平/先决条件:本教程非常适合那些刚接触 OpenMP 并行编程的人。需要对 C 语言或 Fortran 语言中的并行编程有基本的了解。对于那些通常不熟悉并行编程的人来说,EC3500: 并行计算导论中的材料将会很有帮助。
2、简介
2.1、什么是OpenMP
OpenMP是:
- 一种应用程序接口(API),可用于显式地指示多线程、共享内存并行性。
- 由三个主要的API组件组成:
- 编译器指令
- 运行时库函数
- 环境变量
- Open Multi-Processing的缩写
OpenMP的目标
- 标准化
- 在各种共享内存架构/平台之间提供一个标准。
- 由一组主要的计算机硬件和软件供应商联合定义和认可。
- 至精至简
- 为共享内存机器建立一组简单且有限的指令。
- 重要的并行性可以通过使用3或4个指令来实现。
- 显然,随着每个新版本的发布,这个目标变得越来越没有意义。
- 易用性
- 提供以增量方式并行化串行程序的能力,这与通常需要全有或全无方法的消息传递库不同。
- 提供实现粗粒度和细粒度并行的能力。
- 可移植性
- 为 C/C++ 和 FORTRAN 指定API。
- 大多数主要平台已经实现,包括Unix/Linux平台和Windows。
注意:本教程参考了OpenMP 3.1版。新版本的语法和特性目前还没有涉及。
3、OpenMP编程模型
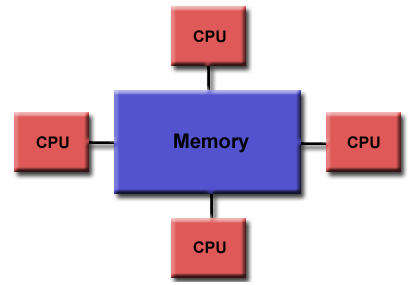
3.1、共享内存模型
- OpenMP是为多处理器或多核共享内存机器设计的。底层架构可以是共享内存
UMA或NUMA。
| Uniform Memory Access 一致内存访问 | Uniform Memory Access 非一致内存访问 |
|---|---|
 |
 |
- 因为OpenMP是为共享内存并行编程而设计的,所以它在很大程度上局限于单节点并行性。通常,节点上处理元素(核心)的数量决定了可以实现多少并行性。
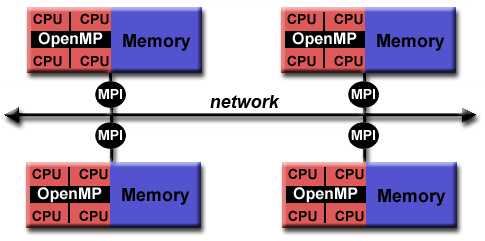
3.2、在 HPC 中使用 OpenMP 的动机
- OpenMP本身的并行性仅限于单个节点。
- 对于高性能计算(HPC - High Performance Computing)应用程序,OpenMP 与 MPI 相结合以实现分布式内存并行。这通常被称为混合并行编程。
- OpenMP 用于每个节点上的计算密集型工作。
- MPI 用于实现节点之间的通信和数据共享。
- 这使得并行性可以在集群的整个范围内实现。
| Hybrid OpenMP-MPI Parallelism |
|---|
 |
3.3、基于线程的并行性
- OpenMP 程序仅通过使用线程来实现并行性。
- 执行线程是操作系统可以调度的最小处理单元。一种可以自动运行的子程序,这个概念可能有助于解释什么是线程。
- 线程存在于单个进程的资源中。没有这个进程,它们就不复存在。
- 通常,线程的数量与机器处理器/核心的数量相匹配。但是,线程的实际使用取决于应用程序。
3.4、显式并行性
- OpenMP 是一个显式的(而不是自动的)编程模型,为程序员提供了对并行化的完全控制。
- 并行化可以像获取串行程序和插入编译器指令一样简单…
- 或者像插入子程序来设置多个并行级别、锁甚至嵌套锁一样复杂
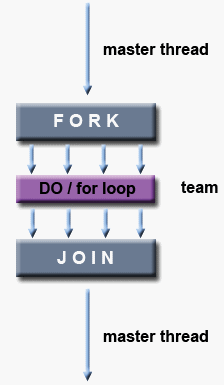
3.5、Fork - Join 模型
- OpenMP 使用并行执行的
fork-join模型:

- 所有 OpenMP 程序都开始于一个主线程。主线程按顺序执行,直到遇到第一个并行区域结构。
- FORK:主线程然后创建一组并行线程。
- 之后程序中由并行区域结构封装的语句在各个团队线程中并行执行。
- JOIN:当团队线程完成并行区域结构中的语句时,它们将进行同步并终止,只留下主线程。
- 并行区域的数量和组成它们的线程是任意的。
3.6、数据范围
- 因为 OpenMP 是共享内存编程模型,所以在默认情况下,并行区域中的大多数数据都是共享的。
- 一个并行区域中的所有线程都可以同时访问共享数据。
- OpenMP 为程序员提供了一种方法,可以在不需要默认共享范围的情况下显式地指定数据的“作用域”。
- 数据范围属性子句将更详细地讨论这个主题。
3.7、嵌套的并行性
- 该 API 提供了在其他并行区域内放置并行区域的方法。
- 实现可能支持这个特性,也可能不支持。
3.8、动态线程
- 该 API 为运行时环境提供了动态更改线程数量的功能,这些线程用于执行并行区域。如有可能,旨在促进更有效地利用资源。
- 实现可能支持这个特性,也可能不支持。
3.9、I/O
- OpenMP 没有指定任何关于并行 I/O 的内容。如果多个线程试图从同一个文件进行写/读操作,这一点尤其重要。
- 如果每个线程都对不同的文件执行 I/O,那么问题就不那么重要了。
- 完全由程序员来确保在多线程程序的上下文中正确地执行 I/O。
3.10、内存模型:经常刷新?
- OpenMP 提供了线程内存的“宽松一致性”和“临时”视图(用他们的话说)。换句话说,线程可以“缓存”它们的数据,并且不需要始终与实际内存保持精确的一致性。
- 当所有线程以相同的方式查看共享变量非常重要时,程序员负责确保所有线程根据需要刷新该变量。
4、OpenMP API 概述
4.1、三大构成
- OpenMP 3.1 API 由三个不同的组件组成:
- 编译器指令
- 运行时库函数
- 环境变量
- 后来的一些 API 包含了这三个相同的组件,但是增加了指令、运行时库函数和环境变量的数量。
- 应用程序开发人员决定如何使用这些组件。在最简单的情况下,只需要其中的几个。
- 实现对所有 API 组件的支持各不相同。例如,一个实现可能声明它支持嵌套并行,但是 API 清楚地表明它可能被限制在一个线程上——主线程。不完全符合开发人员的期望?
4.2、编译器指令
- 编译器指令在源代码中以注释的形式出现,编译器会忽略它们,除非您另外告诉它们 — 通常通过指定适当的编译标志,如后面的编译部分所述。
- OpenMP 编译器指令用于各种目的:
- 生成一个并行区域
- 在线程之间划分代码块
- 在线程之间分配循环迭代
- 序列化代码段
- 线程之间的工作同步
- 编译器指令有以下语法:
sentinel directive-name [clause, …]
例如:
#pragma omp parallel default(shared) private(beta, pi) - 后面将详细讨论编译器指令。
4.3、运行时库函数 Run-time Library Routines:
- OpenMP API 包括越来越多的运行时库函数。
- 这些程序用于各种目的:
- 设置和查询线程的数量
- 查询线程的唯一标识符(线程ID)、父线程的标识符、线程团队大小
- 设置和查询动态线程特性
- 查询是否在一个并行区域,以及在什么级别
- 设置和查询嵌套并行性
- 设置、初始化和终止锁以及嵌套锁
- 查询 wall clock time 和分辨率
- 对于 C/C++,所有运行时库函数都是实际的子程序。对于Fortran来说,有些是函数,有些是子程序。例如:
#include <omp.h>
int omp_get_num_threads(void)
4.4、环境变量
- OpenMP 提供了几个环境变量,用于在运行时控制并行代码的执行。
- 这些环境变量可以用来控制这些事情:
- 设置线程数
- 指定如何划分循环交互
- 将线程绑定到处理器
- 启用/禁用嵌套的并行性;设置嵌套并行度的最大级别
- 启用/禁用动态线程
- 设置线程堆栈大小
- 设置线程等待策略
- 设置 OpenMP 环境变量的方法与设置任何其他环境变量的方法相同,并且取决于您使用的是哪种 shell。例如:
csh/tcsh: setenv OMP_NUM_THREADS 8 sh/bash: export OMP_NUM_THREADS=8 - 稍后将在环境变量一节中讨论 OpenMP 环境变量。
4.5、OpenMP代码结构示例
#include <omp.h>
main () {
int var1, var2, var3;
串行代码 `Serial code`
.
.
.
并行区域的开始。派生一组线程。 `Beginning of parallel region. Fork a team of threads.`
指定变量作用域 `Specify variable scoping `
#pragma omp parallel private(var1, var2) shared(var3)
{
由所有线程执行的并行区域 `Parallel region executed by all threads`
.
其他 OpenMP 指令 `Other OpenMP directives`
.
运行时库调用 `Run-time Library calls`
.
所有线程加入主线程并解散 `All threads join master thread and disband`
}
恢复串行代码 `Resume serial code`
.
.
.
}
5、编译 OpenMP 程序
- OpenMP 版本依赖的 GCC 版本
| OpenMP 版本 | GCC版本 |
|---|---|
| OpenMP 5.0 | >= GCC 9.1 |
| OpenMP 4.5 | >= GCC 6.1 |
| OpenMP 4.0 | >= GCC 4.9.0 |
| OpenMP 3.1 | >= GCC 4.7.0 |
| OpenMP 3.0 | >= GCC 4.4.0 |
| OpenMP 2.5 | >= GCC 4.2.0 |
- 查看一系列编译器对 OpenMP 支持的最佳位置:https://www.openmp.org/resources/openmp-compilers-tools
- linux 下编译命令示例:
g++ Test.cpp -o omptest -fopenmp
6、OpenMP 指令
6.1、C/C++ 指令格式
格式
| #pragma omp | directive-name | [clause, …] | newline |
|---|---|---|---|
| 所有 OpenMP C/C++ 指令都需要。 | 一个有效的 OpenMP 指令。必须出现在 pragma 之后和任何子句之前。 |
可选的。除非另有限制,子句可以按任何顺序重复。 | 必需的。在此指令所包含的结构化块之前。 |
示例
#pragma omp parallel default(shared) private(beta, pi)
一般规则
- 区分大小写。
- 指令遵循 C/C++ 编译器指令标准的约定。
- 每个指令只能指定一个指令名。
- 每个指令最多应用于一个后续语句,该语句必须是一个结构化块。
- 长指令行可以通过在指令行的末尾使用反斜杠(“\”)来转义换行符,从而在后续的行中“继续”。
6.2、指令范围
静态(词法)范围
- 在指令后面的结构化块的开始和结束之间以文本形式封装的代码。
- 指令的静态范围不跨越多个程序或代码文件。
孤立的指令
- 一个 OpenMP 指令,独立于另一个封闭指令,称为孤立型指令。它存在于另一个指令的静态(词法)范围之外。
- 将跨越程序和可能的代码文件。
动态范围
- 指令的动态范围包括静态(词法)范围和孤立指令的范围。
为什么这很重要?
- OpenMP 为指令如何相互关联(绑定)和嵌套指定了许多范围规则。
- 如果忽略 OpenMP 绑定和嵌套规则,可能会导致非法或不正确的程序。
- 有关详细信息,请参阅指令绑定和嵌套规则。
6.3、并行区域结构
目的
- 并行区域是由多个线程执行的代码块。这是基本的 OpenMP 并行结构。
格式
#pragma omp parallel [clause ...] newline
if (scalar_expression)
private (list)
shared (list)
default (shared | none)
firstprivate (list)
reduction (operator: list)
copyin (list)
num_threads (integer-expression)
structured_block
注意
- 当一个线程执行到一个并行指令时,它创建一个线程组并成为该线程组的主线程。主线程是该团队的成员,在该团队中线程号为0。
- 从这个并行区域开始,代码被复制,所有线程都将执行该代码。
- 在并行区域的末端有一个隐含的屏障。只有主线程在此之后继续执行。
- 如果任何线程在一个并行区域内终止,则团队中的所有线程都将终止,并且在此之前所做的工作都是未定义的。
有多少线程
- 并行区域内的线程数由以下因素决定,按优先级排序:
IF子句的计算NUM_THREADS子句的设置- 使用
omp_set_num_threads()库函数 - 设置
OMP_NUM_THREADS环境变量 - 实现缺省值 — 通常是一个节点上的 cpu 数量,尽管它可以是动态的(参见下一小节)
- 线程的编号从0(主线程)到N-1。
动态线程
- 使用
omp_get_dynamic()库函数来确定是否启用了动态线程。 - 如果支持的话,启用动态线程的两种方法是:
omp_set_dynamic()库函数- 将 OMP_NESTED 环境变量设置为 TRUE
- 如果不支持,则在另一个并行区域内嵌套一个并行区域,从而在默认情况下创建一个由单个线程组成的新团队。
子句
- IF 子句:如果存在,它的值必须为非零,以便创建一个线程组。否则,该区域将由主线程串行执行。
- 其余的子句稍后将在数据范围属性子句一节中详细描述。
限制条件
- 并行区域必须是不跨越多个程序或代码文件的结构化块。
- 从一个并行区域转入或转出是非法的。
- 只允许一个
IF子句。 - 只允许一个
NUM_THREADS子句。 - 程序不能依赖于子句的顺序。
并行区域例子
- 简单的“Hello World”程序
- 每个线程执行包含在并行区域中的所有代码。
- OpenMP 库函数用于获取线程标识符和线程总数。
#include <stdio.h> #include <omp.h> int main(int argc, char *argv[]) { int nthreads, tid; /* Fork a team of threads with each thread having a private tid variable */ #pragma omp parallel private(tid) { /* Obtain and print thread id */ tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); /* Only master thread does this */ if (tid == 0) { nthreads = omp_get_num_threads(); printf("Number of threads = %d\n", nthreads); } } /* All threads join master thread and terminate */ return 0; }
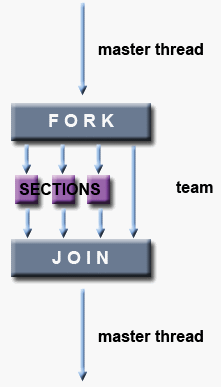
6.4、工作共享结构
- 工作共享结构将封闭代码区域的执行划分给遇到它的团队成员。
- 工作共享结构不会启动新线程。
- 在进入工作共享结构时没有隐含的屏障,但是在工作共享结构的末尾有一个隐含的屏障。
工作共享结构的类型:
- DO / for - 整个团队的循环迭代。表示一种“数据并行性”。
- SECTIONS - 把工作分成单独的、不连续的部分。每个部分由一个线程执行。可以用来实现一种“函数并行性”。
- SINGLE - 序列化一段代码。
| DO/for loop | SECTIONS | SINGLE |
|---|---|---|
 |
 |
|
限制条件
- 为了使指令能够并行执行,必须将工作共享结构动态地封装在一个并行区域中。
- 团队的所有成员都必须遇到工作共享结构,或者根本不遇到。
- 团队的所有成员必须以相同的顺序遇到连续的工作共享结构。
6.4.1、DO / for 指令
目的
- DO / for 指令指定紧随其后的循环迭代必须由团队并行执行。这假定已经启动了并行区域,否则它将在单个处理器上串行执行。
格式
#pragma omp for [clause ...] newline
schedule (type [,chunk])
ordered
private (list)
firstprivate (list)
lastprivate (list)
shared (list)
reduction (operator: list)
collapse (n)
nowait
for_loop
子句
-
schedule:描述循环迭代如何在团队中的线程之间进行分配。默认的调度是依赖于实现的。有关如何使一种调度比其他调度更优的讨论,请参见http://openmp.org/forum/viewtopic.php?f=3&t=83 。
-
静态(STATIC) - 循环迭代被分成小块,然后静态地分配给线程。如果没有指定 chunk,则迭代是均匀地(如果可能)在线程之间连续地划分。

-
动态(DYNAMIC) - 循环迭代分成小块,并在线程之间动态调度;当一个线程完成一个块时,它被动态地分配给另一个块。默认块大小为1。

-
引导(GUIDED) - 当线程请求迭代时,迭代被动态地分配给块中的线程,直到没有剩余的块需要分配为止。与 DYNAMIC 类似,只是每次将一个工作包分配给一个线程时,块的大小就会减小。
初始块的大小与number_of_iteration / number_of_threads成比例
后续块与number_of_iterations_remaining / number_of_threads成比例
chunk 参数定义最小块大小。默认块大小为1。
注意:编译器的实现方式不同,如下面的“Guided A”和“Guided B”示例所示。

- 运行时(RUNTIME) - 环境变量
OMP_SCHEDULE将调度决策延迟到运行时。为这个子句指定块大小是非法的。 - 自动(AUTO) - 调度决策被委托给编译器或运行时系统。
-
-
nowait: 如果指定,那么线程在并行循环结束时不会同步。
-
ordered:指定循环的迭代必须像在串行程序中一样执行。
-
collapse:指定在一个嵌套循环中有多少个循环应该折叠成一个大的迭代空间,并根据
schedule子句进行划分。折叠迭代空间中的迭代的顺序是确定的,就好像它们是按顺序执行的一样。可能会提高性能。 -
其他子句稍后将在数据范围属性子句一节中详细描述。
限制条件
- DO 循环不能是 DO WHILE 循环,也不能是没有循环控制的循环。此外,循环迭代变量必须是整数,并且对于所有线程,循环控制参数必须相同。
- 程序的正确性不能依赖于哪个线程执行特定的迭代。
- 在与 DO / for 指令关联的循环中跳转(转到)是非法的。
- 块大小必须指定为循环不变的整数表达式,因为在不同线程求值期间不存在同步。
ORDERED、COLLAPSE、SCHEDULE子句可以出现一次。- 有关其他限制,请参阅 OpenMP 规范文档。
DO / for 指令示例
- 简单的 vector 相加程序
- 数组
A、B、C和变量N将由所有线程共享。 - 变量
i对每个线程都是私有的;每个线程都有自己唯一的副本。 - 循环迭代将在
CHUNK大小的块中动态分布。 - 线程在完成各自的工作后将不会同步 (
NOWAIT)。
- 数组
#include <omp.h>
#define N 1000
#define CHUNKSIZE 100
int main(int argc, char *argv[]) {
int i, chunk;
float a[N], b[N], c[N];
/* Some initializations */
for (i = 0; i < N; i++)
a[i] = b[i] = i * 1.0;
chunk = CHUNKSIZE;
#pragma omp parallel shared(a,b,c,chunk) private(i)
{
#pragma omp for schedule(dynamic,chunk) nowait
for (i = 0; i < N; i++)
c[i] = a[i] + b[i];
} /* end of parallel region */
return 0;
}
6.4.2 sections 指令
目的
sections指令是一个非迭代的工作共享结构。它指定所包含的代码段将被分配给团队中的各个线程。- 独立的
section指令嵌套在sections指令中。每个部分由团队中的一个线程执行一次。不同的部分可以由不同的线程执行。如果一个线程执行多个部分的速度足够快,并且实现允许这样做,那么它就可以执行多个部分。
格式
#pragma omp sections [clause ...] newline
private (list)
firstprivate (list)
lastprivate (list)
reduction (operator: list)
nowait
{
#pragma omp section newline
structured_block
#pragma omp section newline
structured_block
}
子句
- 除非使用了
NOWAIT/nowait子句,否则在sections指令的末尾有一个隐含的屏障(译者注:an implied barrier意思应该是线程会相互等待)。 - 稍后将在数据范围属性子句一节中详细描述子句。
限制条件
- 跳转(转到)或跳出
section代码块是非法的。 section指令必须出现在一个封闭的sections指令的词法范围内(没有独立部分)。
sections 指令示例
- 下面一个简单的程序演示不同的工作块将由不同的线程完成。
#include <omp.h> #define N 1000 int main() { int i; float a[N], b[N], c[N], d[N]; /* Some initializations */ for (i = 0; i < N; i++) { a[i] = i * 1.5; b[i] = i + 22.35; } #pragma omp parallel shared(a,b,c,d) private(i) { #pragma omp sections nowait { #pragma omp section for (i = 0; i < N; i++) c[i] = a[i] + b[i]; #pragma omp section for (i = 0; i < N; i++) d[i] = a[i] * b[i]; } /* end of sections */ } /* end of parallel region */ return 0; }
6.4.3 single 指令
目的
single指令指定所包含的代码仅由团队中的一个线程执行。- 在处理非线程安全的代码段(如 I/O )时可能很有用
格式
#pragma omp single [clause ...] newline
private (list)
firstprivate (list)
nowait
structured_block
子句
- 除非指定了
nowait子句,否则团队中不执行single指令的线程将在代码块的末尾等待。 - 稍后将在数据范围属性子句一节中详细描述子句。
限制条件
- 进入或跳出一个
single代码块是非法的。
6.5 合并并行工作共享结构
- OpenMP 提供了三个简单的指令:
parallel forparallel sectionsPARALLEL WORKSHARE(fortran only)
- 在大多数情况下,这些指令的行为与单独的并行指令完全相同,并行指令后面紧跟着一个单独的工作共享指令。
- 大多数适用于这两个指令的规则、条款和限制都是有效的。有关详细信息,请参阅 OpenMP API。
- 下面显示了一个使用
parallel for组合指令的示例。#include <omp.h> #define N 1000 #define CHUNKSIZE 100 int main() { int i, chunk; float a[N], b[N], c[N]; /* Some initializations */ for (i = 0; i < N; i++) a[i] = b[i] = i * 1.0; chunk = CHUNKSIZE; #pragma omp parallel for shared(a,b,c,chunk) private(i) schedule(static,chunk) for (i = 0; i < N; i++) c[i] = a[i] + b[i]; return 0; }
6.6 任务结构
目的
- 任务结构定义了一个显式任务,该任务可以由遇到的线程执行,也可以由团队中的任何其他线程延迟执行。
- 任务的数据环境由数据共享属性子句确定。
- 任务执行取决于任务调度 — 详细信息请参阅 OpenMP 3.1 规范文档
- 有关
taskyield和taskwait指令,请参阅 OpenMP 3.1 文档。
格式
#pragma omp task [clause ...] newline
if (scalar expression)
final (scalar expression)
untied
default (shared | none)
mergeable
private (list)
firstprivate (list)
shared (list)
structured_block
子句和限制条件
- 详细信息请参阅 OpenMP 3.1 规范文档。
6.7 同步结构
- 考虑一个简单的例子,两个线程都试图同时更新变量x:
| THREAD1 | THREAD2 |
|---|---|
| update(x) { x = x + 1 } x = 0 update(x) print(x) |
update(x) { x = x + 1 } x = 0 update(x) print(x) |
- 一种可能的执行顺序:
- 线程1初始化
x为0并调用 - 线程1将
x加1,x现在等于1 - 线程2初始化
x为0并调用update(x),x现在等于0 - 线程1输出
x,它等于0而不是1 - 线程2将
x加1,x现在等于1 - 线程2打印
x为1
- 线程1初始化
- 为了避免这种情况,必须在两个线程之间同步
x的更新,以确保产生正确的结果。 - OpenMP 提供了各种同步结构,这些构造控制每个线程相对于其他团队线程的执行方式。
6.7.1 master 指令
目的
master指令指定了一个区域,该区域只由团队的主线程执行。团队中的所有其他线程都将跳过这部分代码。- 这个指令没有隐含的障碍(
implied barrier)。
格式
#pragma omp master newline
structured_block
限制条件
- 进入或跳出一个
master代码块是非法的。
6.7.2 critical 指令
目的
critical指令指定了一个只能由一个线程执行的代码区域。
格式
#pragma omp critical [ name ] newline
structured_block
注意事项
- 如果一个线程当前在一个
critical区域内执行,而另一个线程到达该critical区域并试图执行它,那么它将阻塞,直到第一个线程退出该critical区域。 - 可选的名称使多个不同的临界区域存在:
- 名称充当全局标识符。具有相同名称的不同临界区被视为相同的区域。
- 所有未命名的临界段均视为同一段。
限制条件
- 进入或跳出一个
critical代码块是非法的。 Fortran only: The names of critical constructs are global entities of the program. If a name conflicts with any other entity, the behavior of the program is unspecified.
critical 结构示例
- 团队中的所有线程都将尝试并行执行,但是由于
x的增加由critical结构包围,在任何时候只有一个线程能够读/增量/写x。#include <omp.h> int main() { int x; x = 0; #pragma omp parallel shared(x) { #pragma omp critical x = x + 1; } /* end of parallel region */ return 0; }
6.7.3 barrier 指令
目的
barrier指令同步团队中的所有线程。- 当到达
barrier指令时,一个线程将在该点等待,直到所有其他线程都到达了barrier指令。然后,所有线程继续并行执行barrier之后的代码。
格式
#pragma omp barrier newline
限制条件
- 团队中的所有线程(或没有线程)都必须执行
barrier区域。 - 对于团队中的每个线程,遇到的
work-sharing区域和barrier区域的顺序必须是相同的。
6.7.4 taskwait 指令
目的
- OpenMP 3.1 特性
taskwait结构指定自当前任务开始以来生成的子任务完成时的等待时间。
格式
#pragma omp taskwait newline
限制条件
- 因为
taskwait结构是一个独立的指令,所以它在程序中的位置有一些限制。taskwait指令只能放置在允许使用基本语言语句的地方。taskwait指令不能代替if、while、do、switch或label后面的语句。有关详细信息,请参阅 OpenMP 3.1 规范文档。
6.7.5 atomic 指令
目的
atomic结构确保以原子方式访问特定的存储位置,而不是将其暴露给多个线程同时读写,这些线程可能会导致不确定的值。本质上,这个指令提供了一个最小临界(mini-CRITICAL)区域。
格式
#pragma omp atomic [ read | write | update | capture ] newline
statement_expression
限制条件
- 该指令仅适用于紧接其后的单个语句。
- 原子语句必须遵循特定的语法。查看最新的OpenMP规范。
6.7.6 flush 指令
目的
flush指令标识了一个同步点,在这个点上,内存数据必须一致。这时,线程可见的变量被写回内存。- 请参阅最新的 OpenMP 规范以获取详细信息。
格式
#pragma omp flush (list) newline
注意事项
- 可选 list 参数包含一个将被刷新的已命名变量列表,以避免刷新所有变量。对于列表中的指针,请注意指针本身被刷新,而不是它指向的对象。
- 实现必须确保线程可见变量的任何修改在此之后对所有线程都是可见的,例如编译器必须将值从寄存器恢复到内存,硬件可能需要刷新写缓冲区,等等。
- 对于下面的指令,将使用
flush指令。如果存在nowait子句,则该指令无效。barrierparallel- 进入和退出critical- 进入和退出ordered- 进入和退出for- 退出sections- 退出single- 退出
6.7.7 ordered 指令
目的
ordered指令指定封闭的循环迭代将以串行处理器上执行顺序执行。- 如果之前的迭代还没有完成,线程在执行它们的迭代块之前需要等待。
- 在带有
ordered子句的for循环中使用。 ordered指令提供了一种“微调”的方法,其中在循环中应用了排序。否则,它不是必需的。
格式
#pragma omp for ordered [clauses...]
(loop region)
#pragma omp ordered newline
structured_block
(endo of loop region)
限制条件
- 一个
ordered指令只能在以下指令的动态范围内出现:for或者parallel for(C/C++)。
- 在一个有序的区段中,任何时候都只允许一个线程。
- 进入或跳出一个
ordered代码块是非法的。 - 一个循环的迭代不能多次执行同一个有序指令,也不能一次执行多个有序指令。
- 包含有序指令的循环必须是带有
ordered子句的循环。
6.8 threadprivate 指令
目的
threadprivate指令指定复制变量,每个线程都有自己的副本。- 可用于通过执行多个并行区域将全局文件作用域变量(C/C++/Fortran)或公共块(Fortran)局部化并持久化到一个线程。
格式
#pragma omp threadprivate (list)
注意事项
- 指令必须出现在列出的变量/公共块的声明之后。每个线程都有自己的变量/公共块的副本,所以一个线程写的数据对其他线程是不可见的。
- 在第一次进入一个并行区域时,应该假设
threadprivate变量和公共块中的数据是未定义的,除非在并行指令中指定了copyin子句。 threadprivate变量不同于private变量(稍后讨论),因为它们能够在代码的不同并行区域之间持久存在。
示例
#include <stdio.h>
#include <omp.h>
int a, b, i, tid;
float x;
#pragma omp threadprivate(a, x)
int main() {
/* 显式关闭动态线程 Explicitly turn off dynamic threads */
omp_set_dynamic(0);
printf("1st Parallel Region:\n");
#pragma omp parallel private(b,tid)
{
tid = omp_get_thread_num();
a = tid;
b = tid;
x = 1.1 * tid + 1.0;
printf("Thread %d: a,b,x= %d %d %f\n", tid, a, b, x);
} /* end of parallel region */
printf("************************************\n");
printf("Master thread doing serial work here\n");
printf("************************************\n");
printf("2nd Parallel Region:\n");
#pragma omp parallel private(tid)
{
tid = omp_get_thread_num();
printf("Thread %d: a,b,x= %d %d %f\n", tid, a, b, x);
} /* end of parallel region */
return 0;
}
Output:
1st Parallel Region:
Thread 4: a,b,x= 4 4 5.400000
Thread 7: a,b,x= 7 7 8.700000
Thread 2: a,b,x= 2 2 3.200000
Thread 3: a,b,x= 3 3 4.300000
Thread 6: a,b,x= 6 6 7.600000
Thread 1: a,b,x= 1 1 2.100000
Thread 5: a,b,x= 5 5 6.500000
Thread 0: a,b,x= 0 0 1.000000
************************************
Master thread doing serial work here
************************************
2nd Parallel Region:
Thread 1: a,b,x= 1 0 2.100000
Thread 6: a,b,x= 6 0 7.600000
Thread 4: a,b,x= 4 0 5.400000
Thread 5: a,b,x= 5 0 6.500000
Thread 2: a,b,x= 2 0 3.200000
Thread 7: a,b,x= 7 0 8.700000
Thread 0: a,b,x= 0 0 1.000000
Thread 3: a,b,x= 3 0 4.300000
限制条件
- 只有在动态线程机制“关闭”并且不同并行区域中的线程数量保持不变的情况下,
threadprivate对象中的数据才能保证持久。动态线程的默认设置是未定义的。 Fortran: common block names must appear between slashes: /cb/- 有关这里没有列出的其他限制,请参阅最新的 OpenMP 规范。
6.9 数据范围属性子句
- 也称为数据共享属性子句。
- OpenMP 编程的一个重要考虑是理解和使用数据作用域。
- 因为 OpenMP 是基于共享内存编程模型的,所以大多数变量在默认情况下是共享的。
- 全局变量包括:
Fortran: COMMON blocks, SAVE variables, MODULE variables- 文件作用域变量,
static
- 私有变量包括:
- 循环索引变量
- 从并行区域调用的子程序中的堆栈变量
Fortran: Automatic variables within a statement block
- OpenMP 数据范围属性子句用于显式定义变量的范围。它们包括:
privatefirstprivatelastprivateshareddefaultreductioncopyin
- 数据范围属性子句与几个指令(
parallel、DO/for和sections)一起使用,以控制所包含变量的范围。 - 这些结构提供了在并行结构执行期间控制数据环境的能力。
- 它们定义了如何将程序的串行部分中的哪些数据变量传输到程序的并行区域(以及向后传输)
- 它们定义哪些变量将对并行区域中的所有线程可见,哪些变量以私有形式分配给所有线程。
- 数据范围属性子句仅在其词法/静态范围内有效。
- 重要事项:请参阅最新的 OpenMP 规范,以了解关于此主题的重要细节和讨论。
- 为了方便起见,提供了一个子句/指令汇总表。
6.9.1 private 子句
目的
private子句将在其列表中的变量声明为每个线程的私有变量。
格式
private (list)
注意事项
- 私有变量的行为如下:
- 为团队中的每个线程声明一个相同类型的新对象
- 所有对原始对象的引用都被替换为对新对象的引用
- 应该假定每个线程都没有初始化
6.9.2 shared 子句
目的
shared子句声明其列表中的变量在团队中的所有线程之间共享。
格式
shared (list)
注意事项
- 共享变量只存在于一个内存位置,所有线程都可以读写该地址
- 程序员有责任确保多个线程正确地访问共享变量(例如通过临界区)
6.9.3 default 子句
目的
default子句允许用户为任何并行区域的词法范围内的所有变量指定默认作用域。
格式
default (shared | none)
注意事项
- 使用
private、shared、firstprivate、lastprivate和reduction子句可以避免使用特定变量。 - C/C++ OpenMP 规范不包括将
private或firstprivate作为可能的默认值。但是,实际的实现可能会提供这个选项。 - 使用
none作为默认值要求程序员显式地限定所有变量的作用域。
限制条件
- 在并行指令上只能指定一个
default子句
6.9.4 firstprivate 子句
目的
firstprivate子句将private子句的行为与它的列表中变量的自动初始化相结合。
格式
firstprivate (list)
注意事项
- 在进入并行或工作共享结构之前,将根据其原始对象的值初始化列出的变量。
6.9.5 lastprivate 子句
目的
lastprivate子句将private子句的行为与从最后一个循环迭代或部分到原始变量对象的复制相结合。
格式
lastprivate (list)
注意事项
- 复制回原始变量对象的值是从封闭结构的最后一次(顺序)迭代或部分获得的。
- 例如,为
DO部分执行最后一次迭代的团队成员,或者执行sections上下文的最后一部分的团队成员,使用其自身的值执行副本。
6.9.6 copyin 子句
目的
copyin子句提供了为团队中的所有线程分配相同值的threadprivate变量的方法。
格式
copyin (list)
注意事项
- 列表包含要复制的变量的名称。在Fortran中,列表既可以包含公共块的名称,也可以包含已命名变量的名称。
- 主线程变量用作复制源。在进入并行结构时,将使用其值初始化团队线程。
6.9.7 copyprivate 子句
目的
copyprivate子句可用于将单个线程获得的值直接传播到其他线程中私有变量的所有实例。- 与
single指令相关联 - 有关更多的讨论和示例,请参阅最新的 OpenMP 规范文档。
格式
copyprivate (list)
6.9.8 reduction 子句
目的
reduction子句对出现在其列表中的变量执行约简操作。- 为每个线程创建并初始化每个列表变量的私有副本。在约简结束时,将约简变量应用于共享变量的所有私有副本,并将最终结果写入全局共享变量。
格式
reduction (operator: list)
Example: REDUCTION - Vector Dot Product:
- 并行循环的迭代将以相同大小的块分配给团队中的每个线程(调度静态)
- 在并行循环构造的末尾,所有线程将添加它们的“result”值来更新主线程的全局副本。
#include <stdio.h> #include <omp.h> int main() { int i, n, chunk; float a[100], b[100], result; /* Some initializations */ n = 100; chunk = 10; result = 0.0; for (i = 0; i < n; i++) { a[i] = i * 1.0; b[i] = i * 2.0; } #pragma omp parallel for default(shared) private(i) \ schedule(static,chunk) reduction(+:result) for (i = 0; i < n; i++) result = result + (a[i] * b[i]); printf("Final result= %f\n", result); return 0; }
限制条件
- 列表项的类型必须对约简操作符有效。
- 列表项/变量不能声明为共享或私有。
- 约简操作可能与实数无关。
- 有关其他限制,请参见 OpenMP 标准 API。
6.10 子句/指令汇总表
- 下表总结了哪些子句被哪些OpenMP指令接受。
| Clause | parallel | for | sections | single | parallel for | parallel sections |
|---|---|---|---|---|---|---|
| if | √ | √ | √ | |||
| private | √ | √ | √ | √ | √ | √ |
| shared | √ | √ | √ | √ | ||
| default | √ | √ | √ | |||
| firstprivate | √ | √ | √ | √ | √ | √ |
| lastprivate | √ | √ | √ | √ | ||
| reduction | √ | √ | √ | √ | √ | |
| copyin | √ | √ | √ | |||
| copyprivate | √ | |||||
| schedule | √ | √ | ||||
| ordered | √ | √ | ||||
| nowait | √ | √ | √ |
- 以下 OpenMP 指令不接受子句:
mastercriticalbarrieratomicflushorderedthreadprivate
- 实现可能(也确实)与每个指令所支持的子句的标准不同。
6.11 指令绑定和嵌套规则
- 本节主要是作为管理 OpenMP 指令和绑定的规则的快速参考。用户应该参考他们的实现文档和 OpenMP 标准以了解其他规则和限制。
- 除非另有说明,规则适用于 Fortran 和 C/C++ OpenMP 实现。
- 注意:Fortran API 还定义了许多数据环境规则。这些没有在这里复制。
指令绑定
DO/for、sections、single、master和barrier指令绑定到动态封闭的parallel(如果存在的话)。如果当前没有并行区域被执行,指令就没有效果。- 有序指令绑定到动态封闭的
DO/for。 atomic指令强制对所有线程中的atomic指令进行独占访问,而不仅仅是当前的团队。critical指令强制对所有线程中的critical指令进行独占访问,而不仅仅是当前的团队。- 指令永远不能绑定到最接近的封闭并行之外的任何指令。
指令嵌套
- 工作共享区域不能紧密嵌套在工作共享、显式任务、关键区域、有序区域、原子区域或主区域内。
- 屏障区域不能紧密嵌套在工作共享、显式任务、关键区域、有序区域、原子区域或主区域中。
- 主区域不能紧密嵌套在工作共享、原子或显式任务区域内。
- 有序区域可能不会紧密嵌套在临界、原子或显式任务区域内。
- 一个有序区域必须与一个有序子句紧密嵌套在一个循环区域(或并行循环区域)内。
- 临界区不能嵌套(紧密嵌套或以其他方式嵌套)在具有相同名称的临界区内。注意,此限制不足以防止死锁。
- 并行、刷新、临界、原子、taskyield 和显式任务区域可能不会紧密嵌套在原子区域内。
7、运行时库函数
概述
- OpenMP API 包括越来越多的运行时库函数。
- 这些函数有多种用途,如下表所示:
| Routine | Purpose |
|---|---|
opm_set_num_threads |
设置将在下一个并行区域中使用的线程数 |
opm_get_num_threads |
返回当前在团队中执行并行区域的线程数,该区域是调用该线程的地方 |
opm_get_max_threads |
返回可通过调用 opm_get_num_threads 函数返回的最大值 |
opm_get_thread_num |
返回在团队中执行此调用的线程的线程号 |
opm_get_thread_limit |
返回程序可用的 OpenMP 线程的最大数量 |
opm_get_num_procs |
返回程序可用的处理器数量 |
opm_in_parallel |
用于确定正在执行的代码段是否并行 |
opm_set_dynamic |
启用或禁用(由运行时系统)可用于执行并行区域的线程数的动态调整 |
opm_get_dynamic |
用于确定是否启用动态线程调整 |
opm_set_nested |
用于启用或禁用嵌套并行性 |
opm_get_nested |
用于确定是否启用嵌套并行性 |
opm_set_schedule |
在 OpenMP 指令中将“runtime”用作调度类型时,设置循环调度策略 |
opm_get_schedule |
当 OpenMP 指令中使用“runtime”作为调度类型时,返回循环调度策略 |
opm_set_max-active_levels |
设置嵌套并行区域的最大数目 |
opm_get_max-active_levels |
返回嵌套并行区域的最大数目 |
opm_get_level |
返回嵌套并行区域的当前级别 |
opm_get_ancestor_thread_num |
对于当前线程的给定嵌套级别,返回祖先线程的线程数 |
opm_get_team_size |
对于当前线程的给定嵌套级别,返回线程团队的大小 |
opm_get_active_level |
返回包含调用的任务的嵌套活动并行区域的数目 |
opm_in_final |
如果程序在最后一个任务区域执行,则返回true;否则返回false |
opm_init_lock |
初始化与锁变量关联的锁 |
opm_destory_lock |
将给定的锁变量与任何锁分离 |
opm_set_lock |
获得锁的所有权 |
opm_unset_lock |
释放锁 |
opm_test_lock |
尝试设置锁,但如果锁不可用,则不会阻塞 |
opm_init_nest_lock |
初始化与锁变量关联的嵌套锁 |
opm_destory_nest_lock |
将给定的嵌套锁变量与任何锁分离 |
opm_set_nest_lock |
获取嵌套锁的所有权 |
opm_unset_nest_lock |
释放嵌套锁 |
opm_test_nest_lock |
尝试设置嵌套锁,但如果锁不可用,则不会阻塞 |
opm_get_wtime |
提供便携式挂钟定时程序 |
opm_get_wtick |
返回一个双精度浮点值,该值等于连续时钟滴答之间的秒数 |
- 对于C/C++,所有运行时库函数都是实际的子程序。对于Fortran来说,有些是函数,有些是子程序。例如:
#include <omp.h>
int omp_get_num_threads(void)
- 注意,对于C/C++,通常需要包含
<omp.h >头文件。 - Fortran例程不区分大小写,但C/C++例程区分大小写。
- 对于锁程序/函数:
- 锁变量只能通过锁程序访问
- 对于Fortran,锁变量的类型应该是integer,并且要足够大,以便容纳一个地址。
- 对于C/C++,lock 变量的类型必须是
omp_lock_t或omp_nest_lock_t,这取决于所使用的函数。
- 实现注意事项:
- 实现可能支持也可能不支持所有 OpenMP API 特性。例如,如果支持嵌套并行,那么它可能只是名义上的,因为嵌套并行区域可能只有一个线程。
- 有关详细信息,请参阅您的实现文档—或者亲自试验一下,如果您在文档中找不到它,请自己查找。
- 运行时库函数在附录A中有更详细的讨论。
8、环境变量
- OpenMP 提供了以下环境变量来控制并行代码的执行。
- 所有环境变量名都是大写的。分配给它们的值不区分大小写。
OMP_SCHEDULE
只适用于 DO, PARALLEL DO (Fortran)和 for , parallel for (C/C++)指令,它们的 schedule 子句设置为运行时。此变量的值决定如何在处理器上调度循环的迭代。例如:
setenv OMP_SCHEDULE "guided, 4"
setenv OMP_SCHEDULE "dynamic"
OMP_NUM_THREADS
设置执行期间使用的最大线程数。例如:
setenv OMP_NUM_THREADS 8
OMP_DYNAMIC
启用或禁用可用于并行区域执行的线程数量的动态调整。有效值为 TRUE 或 FALSE。例如:
setenv OMP_DYNAMIC TRUE
OMP_PROC_BIND
启用或禁用线程绑定到处理器。有效值为 TRUE 或 FALSE。例如:
setenv OMP_PROC_BIND TRUE
OMP_NESTED
启用或禁用嵌套并行性。有效值为 TRUE 或 FALSE。例如:
setenv OMP_NESTED TRUE
OMP_STACKSIZE
控制已创建(非主)线程的堆栈大小。例子:
setenv OMP_STACKSIZE 2000500B
setenv OMP_STACKSIZE "3000 k "
setenv OMP_STACKSIZE 10M
setenv OMP_STACKSIZE " 10 M "
setenv OMP_STACKSIZE "20 m "
setenv OMP_STACKSIZE " 1G"
setenv OMP_STACKSIZE 20000
OMP_WAIT_POLICY
为 OpenMP 实现提供有关等待线程的所需行为的提示。一个兼容的 OpenMP 实现可能遵守也可能不遵守环境变量的设置。有效值分为 ACTIVE 和 PASSIVE。ACTIVE 指定等待的线程大部分应该是活动的,即,在等待时消耗处理器周期。PASSIVE 指定等待的线程大部分应该是被动的,即,而不是在等待时消耗处理器周期。ACTIVE 和 PASSIVE 行为的细节是由实现定义的。例子:
setenv OMP_WAIT_POLICY ACTIVE
setenv OMP_WAIT_POLICY active
setenv OMP_WAIT_POLICY PASSIVE
setenv OMP_WAIT_POLICY passive
OMP_MAX_ACTIVE_LEVELS
控制嵌套的活动并行区域的最大数目。该环境变量的值必须是非负整数。如果 OMP_MAX_ACTIVE_LEVELS 的请求值大于实现所能支持的嵌套活动并行级别的最大数量,或者该值不是一个非负整数,则该程序的行为是由实现定义的。例子:
setenv OMP_MAX_ACTIVE_LEVELS 2
OMP_THREAD_LIMIT
设置用于整个 OpenMP 程序的 OpenMP 线程的数量。这个环境变量的值必须是正整数。如果 OMP_THREAD_LIMIT 的请求值大于实现所能支持的线程数,或者该值不是正整数,则程序的行为是由实现定义的。例子:
setenv OMP_THREAD_LIMIT 8
9、线程堆栈大小和线程绑定
线程堆栈大小
- OpenMP 标准没有指定一个线程应该有多少堆栈空间。因此,默认线程堆栈大小的实现将有所不同。
- 默认的线程堆栈大小很容易耗尽。它也可以在编译器之间不可移植。以过去版本的LC编译器为例:
| Compiler | Approx. Stack Limit | Approx. Array Size (doubles) |
|---|---|---|
| Linux icc, ifort | 4 MB | 700 x 700 |
| Linux pgcc, pgf90 | 8 MB | 1000 x 1000 |
| Linux gcc, gfortran | 2 MB | 500 x 500 |
- 超出其堆栈分配的线程可能存在或不存在段错误。当数据被破坏时,应用程序可以继续运行。
- 静态链接代码可能受到进一步的堆栈限制。
- 用户的登录shell还可以限制堆栈大小
- 如果您的 OpenMP 环境支持 OpenMP 3.0
OMP_STACKSIZE环境变量(在前一节中介绍过),那么您可以使用它在程序执行之前设置线程堆栈大小。例如:
setenv OMP_STACKSIZE 2000500B
setenv OMP_STACKSIZE "3000 k "
setenv OMP_STACKSIZE 10M
setenv OMP_STACKSIZE " 10 M "
setenv OMP_STACKSIZE "20 m "
setenv OMP_STACKSIZE " 1G"
setenv OMP_STACKSIZE 20000
- 否则,在LC上,您应该能够对Linux集群使用下面的方法。该示例显示将线程堆栈大小设置为12 MB,作为预防措施,将shell堆栈大小设置为无限制。
| env | cmd |
|---|---|
| csh/tcsh | setenv KMP_STACKSIZE 12000000 limit stacksize unlimited |
| ksh/sh/bash | export KMP_STACKSIZE=12000000 ulimit -s unlimited |
线程绑定
- 在某些情况下,如果一个程序的线程被绑定到处理器/核心,那么它的性能会更好。
- “绑定”一个线程到一个处理器意味着操作系统将调度一个线程始终在同一个处理器上运行。否则,可以将线程调度为在任何处理器上执行,并在每个时间片的处理器之间来回“弹回”。
- 也称为“线程关联性”或“处理器关联性”。
- 将线程绑定到处理器可以更好地利用缓存,从而减少昂贵的内存访问。这是将线程绑定到处理器的主要动机。
- 根据平台、操作系统、编译器和 OpenMP 实现的不同,可以通过几种不同的方式将线程绑定到处理器。
- OpenMP 3.1 版 API 提供了一个环境变量来“打开”或“关闭”处理器绑定。例如:
setenv OMP_PROC_BIND TRUE
setenv OMP_PROC_BIND FALSE
- 在更高的级别上,进程也可以绑定到处理器。
- 有关进程和线程绑定到LC Linux集群上的处理器的详细信息,可以在https://lc.llnl.gov/confluence/display/TLCC2/mpibind找到。
10、Monitoring, Debugging and Performance Analysis Tools for OpenMP
11、References and More Information
12、附录A
问题记录
- 编译程序成功,执行程序报错:./a.out: /usr/lib64/libgomp.so.1: version `GOMP_4.5’ not found (required by ./a.out)
原因是libgomp.so.1版本不对
解决方法:
- 查找libgomp.so.1
[root@localhost bin]## find /usr -name libgomp.so.1 /usr/local/lib64/libgomp.so.1 /usr/lib64/libgomp.so.1 - 是否包含
GOMP_4.5strings /usr/local/lib64/libgomp.so.1 | grep GOMP strings /usr/lib64/libgomp.so.1 | grep GOMP - 发现
/usr/local/lib64/libgomp.so.1包含GOMP_4.5,/usr/lib64/libgomp.so.1不包含GOMP_4.5,用包含GOMP_4.5的so进行替换cp /usr/local/lib64/libgomp.so.1 /usr/lib64/libgomp.so.1