1、Go 语言简介
- Go 语言起源 2007 年,并于 2009 年正式对外发布
- Go 语言三位作者:
Robert Griesemer,参与开发 Java HotSpot 虚拟机;Rob Pike,Go 语言项目总负责人,贝尔实验室 Unix 团队成员,参与的项目包括 Plan 9,Inferno 操作系统和 Limbo 编程语言;Ken Thompson,贝尔实验室 Unix 团队成员,C 语言、Unix 和 Plan 9 的创始人之一,与 Rob Pike 共同开发了 UTF-8 字符集规范
- 为什么要创造一门编程语言:
- C/C++ 的发展速度无法跟上计算机发展的脚步,十多年来也没有出现一门与时代相符的主流系统编程语言,因此人们需要一门新的系统编程语言来弥补这个空缺,尤其是在计算机信息时代。
- 相比计算机性能的提升,软件开发领域不被认为发展得足够快或者比硬件发展得更加成功(有许多项目均以失败告终),同时应用程序的体积始终在不断地扩大,这就迫切地需要一门具备更高层次概念的低级语言来突破现状。
- 在 Go 语言出现之前,开发者们总是面临非常艰难的抉择,究竟是使用执行速度快但是编译速度并不理想的语言(如:C++),还是使用编译速度较快但执行效率不佳的语言(如:.NET、Java),或者说开发难度较低但执行速度一般的动态语言呢?显然,Go 语言在这 3 个条件之间做到了最佳的平衡:快速编译,高效执行,易于开发。
- Hello World
package main // Go 程序都组织成包
import "fmt" // import 语句用于导入外部代码。标准库中的 fmt 包用于格式化并输出数据
func main() { // 像 C 语言一样,main 函数是程序执行的入口
fmt.Println("Hello World!")
}
go get github.com/goinaction/code运行示例程序go build,go run main.go
2、基本结构与数据类型
2.1 文件名、关键字、标识符
- 文件后缀名为
.go,由小写字母组成,如果有多个部分,用_分隔,如fmt_test.go - go语言关键字只有25个:
break, default, func, interface, select, case, defer, go, map, struct, chan, else, goto, package, switch, const, fallthrough, if, range, type, continue, for, import, return, var - 还有 36 个预定义标识符:
append, bool, byte, cap, close, complex, complex64, complex128, uint16, copy, false, float32, float64, imag, int, int8, int16, uint32, int32, int64, iota, len, make, new, nil, panic, uint64, print, println, real, recover, string, true, uint, uint8, uintptr - 有效的标识符必须以字母(可以使用任何 UTF-8 编码的字符或 _)开头,然后紧跟着 0 个或多个字符或 Unicode 数字,如:
X56、group1、_x23、i、өԑ12。
2.2 包的概念、导入与可见性
- 如同其它一些编程语言中的类库或命名空间的概念,每个 Go 文件都属于且仅属于一个包。一个包可以由许多以 .go 为扩展名的源文件组成,因此文件名和包名一般来说都是不相同的。
- 必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。
- 如果对一个包进行更改或重新编译,所有引用了这个包的程序都必须全部重新编译。
- 导入包的方式:
import "fmt"
import "os"
import (
"fmt"
"os"
)
- 可见性规则:
- 当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public)
- 标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 private )。
- 可以通过使用包的别名来解决包名之间的名称冲突,如:
import fm "fmt" - 如果导入了一个包却没有使用它,则在编译时会报错,如:
"os" imported but not used
2.3 注释
- 使用和 C 语言一样的注释方式,
//表示单行注释,/**/表示多行注释或块注释
2.4 类型与运算符
- Go 语言类型包括:
int、float32、 float64、bool、string、struct、数组、slice、map、channel、interface。
与操作系统架构无关的类型都有固定的大小,并在类型的名称中就可以看出来:
整数:
int8(-128 -> 127)
int16(-32768 -> 32767)
int32(-2,147,483,648 -> 2,147,483,647)
int64(-9,223,372,036,854,775,808 -> 9,223,372,036,854,775,807)
无符号整数:
uint8(0 -> 255)
uint16(0 -> 65,535)
uint32(0 -> 4,294,967,295)
uint64(0 -> 18,446,744,073,709,551,615)
浮点型(IEEE-754 标准):
float32(+- 1e-45 -> +- 3.4 * 1e38)
float64(+- 5 * 1e-324 -> 107 * 1e308)
- 位运算:
&、|、^、&^(位清除:将指定位置上的值设置为 0) - 一元运算符:
<<、>> - 逻辑运算符:
==、!=、<、<=、>、>= - 算术运算符:
+、-、*、/、%
优先级 运算符
7 ^ !
6 * / % << >> & &^
5 + - | ^
4 == != < <= >= >
3 <-
2 &&
1 ||
- 类型别名:
type newType orgType,如type AGE int
3、变量、常量、指针
3.1 变量
- 声明变量的一般形式是使用
var关键字:var identifier type。 - 为什么将变量类型放到变量名后面:避免像 C 语言中那样含糊不清的声明形式,例如:
int* a, b。 - 当一个变量被声明之后,系统自动赋予它该类型的零值:
int为 0,float为 0.0,bool为 false,string为空字符串,指针为nil。
var a int = 1
// Go 编译器可以根据变量的值来自动推断其类型,在编译时经完成推断过程
var b = 15
var c = false
// 在函数体内声明局部变量时,可使用简短声明语法 :=,不可以用于全局变量的声明与赋值
d := true
// 同一类型的多个变量可以声明在同一行
var e, f int
d, e, f = false, 1, 2
// 多个变量使用 := 声明并初始化
g, h := "abc", false
// 交换2个变量的值
e, f = f, e
- 值类型和引用类型:
int、float、bool、string、数组、结构体属于值类型- 指针、
slice、map、channel属于引用类型
3.2 常量
- 常量使用关键字
const定义,用于存储不会改变的数据。常量的定义格式:const identifier [type] = value
const b string = "abc" // 显式类型定义
const b = "abc" // 隐式类型定义
- 常量还可以用作枚举:
const (
Unknown = 0
Female = 1
Male = 2
)
iota使用方法:
// 第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1,
// 并且没有赋值的常量默认会应用上一行的赋值表达式:
const (
a = iota // a = 0
b = iota // b = 1
c = iota // c = 2
)
// 赋值一个常量时,之后没赋值的常量都会应用上一行的赋值表达式
const (
a = iota // a = 0
b // b = 1
c // c = 2
d = 5 // d = 5
e // e = 5
)
// 赋值两个常量,iota 只会增长一次,而不会因为使用了两次就增长两次
const (
Apple, Banana = iota + 1, iota + 2 // Apple=1 Banana=2
Cherimoya, Durian // Cherimoya=2 Durian=3
Elderberry, Fig // Elderberry=3, Fig=4
)
const (
_ = iota // 使用 _ 忽略不需要的 iota
KB = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
)
4、控制结构
4.1 if-else 结构
a, b := 1, 2
if a > b {
fmt.Println("a > b")
} else if a < b {
fmt.Println("a < b")
} else {
fmt.Println("a == b")
}
- if 和 else 之后的
{必须和关键字同一行,否则编译会报错:syntax error: unexpected newline, expecting { after if clause
4.2 switch结构
// 第一种形式
switch variable { // 变量 variable 可以是任何类型
case value1:
fmt.Println("case value1") // 这里没有 break
case value2:
fmt.Println("case value2")
default:
fmt.Println("default")
}
// 第二种形式,case 中进行条件判断
switch {
case i < 0:
f1()
case i == 0:
f2()
case i > 0:
f3()
}
// 第三种形式,包含一个初始化语句
switch result := calculate(); {
case result < 0:
...
case result > 0:
...
default:
...
}
- 如果在执行完每个分支的代码后,还希望继续执行后续分支的代码,可以使用
fallthrough关键字来达到目的。
switch i {
case 0: fallthrough
case 1:
f() // 当 i == 0 时函数也会被调用
}
4.3 for 结构
// 基本形式
for i := 0; i < 5; i++ {
fmt.Printf("This is the %d iteration\n", i)
}
// 基于条件判断的迭代,类似于其他语言的 while
var i int = 5
for i >= 0 {
i = i - 1
fmt.Printf("The variable i is now: %d\n", i)
}
// 无限循环
for {
// do something
// 需要退出循环,用 break
}
// for-range 结构
var arr = [5]int{1, 2, 3, 4, 5}
for index, value := range arr {
fmt.Println(index, value)
}
5、函数
// 函数定义如下:
func Add(a, b int) int {
return a + b
}
// 假设函数在 utils 包中,则函数调用格式为
utils.Add(1, 2)
// 命名的返回值(尽量使用命名返回值:会使代码更清晰、更简短,同时更加容易读懂。)
func SumAndProduct(a, b int) (sum int, product int) {
sum = a + b
product = a * b
return // 或 return sum, product
}
// 空白符用来匹配一些不需要的值,然后丢弃掉
_, product = utils.SumAndProduct(1, 2) // 丢弃和的结果
// 变长参数,最后一个参数是采用 ...type 的形式
func Min(arr ...int) int {
ans := math.MaxInt32
for _, v := range arr {
if v < ans {
ans = v
}
}
return ans
}
fmt.Println(utils.Min(1, 2, 3))
- Go 语言拥有一些不需要进行导入操作就可以使用的内置函数,如
len、cap、append等
6、数组与切片
数组
- 数组声明和初始化,基本格式:
var identifier [len]type
var nums1 [5]int // 声明大小为5的int数组
var nums2 = new([5]int) // 这种方式声明的数组类型是 *[5]int
var nums3 = [5]int{1, 2, 3, 4, 5} // 声明的同时初始化
nums4 := [5]int{1, 2, 3, 4, 5}
var nums5 = [10]int{1, 2, 3, 4, 5} // 后5个默认为0
var nums6 = [...]int{1, 2, 3} // 使用 ... 代替数组长度
var nums7 = [5]int{1: 10, 2: 20} // [0 10 20 0 0]
var nums8 = [...]int{1: 10, 5: 50} // [0 10 0 0 0 50],最大的索引作为数组长度
var nums9 [2][3]int // 二维数组声明
var nums10 = [2][3]int{ {1, 2, 3}, {4, 5, 6} } // 二维数组声明并初始化
nums11 := [2][3]int{ {1, 2, 3}, {4, 5, 6} }
注意:go 的数组类型是值类型,和 C/C++ 不用,所以将数组传递给函数时,会有内存拷贝,性能较低,且函数内部无法修改数组内容。如果需要修改,调用函数时,传参加 &,如
fun(&arr)
切片
- 切片(slice)是对数组一个连续片段的引用(该数组我们称之为相关数组,通常是匿名的),这个片段可以是整个数组,或者是由起始和终止索引标识的一些项的子集。
// /src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
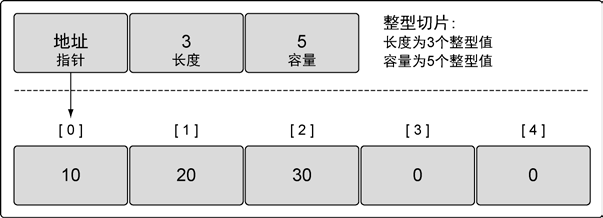
切片创建
var slice1 []int // 不需要说明长度,未初始化默认为nil,长度为0
var arr [6]int
var slice2 []int = arr[2:5] // arr[2], arr[3], arr[4]
var slice3 = []int{1, 2, 3}
slice4 := []int{1, 2, 3}[:]
slice5 := make([]int, 5) // 创建大小和容量为5的切片,值都为0
slice6 := make([]int, 3, 5) // 大小为3,容量为5
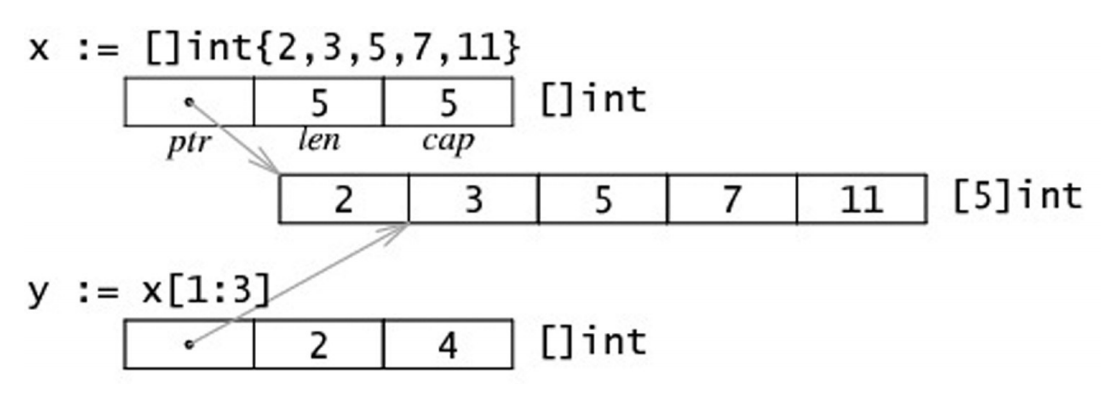
foo = make([]int, 5)
foo[3] = 42
foo[4] = 100
bar := foo[1:4]
bar[1] = 99
- 首先先创建一个foo的slice,其中的长度和容量都是5
- 然后开始对foo所指向的数组中的索引为3和4的元素进行赋值
- 然后,对foo做切片后赋值给bar,再修改bar[1]
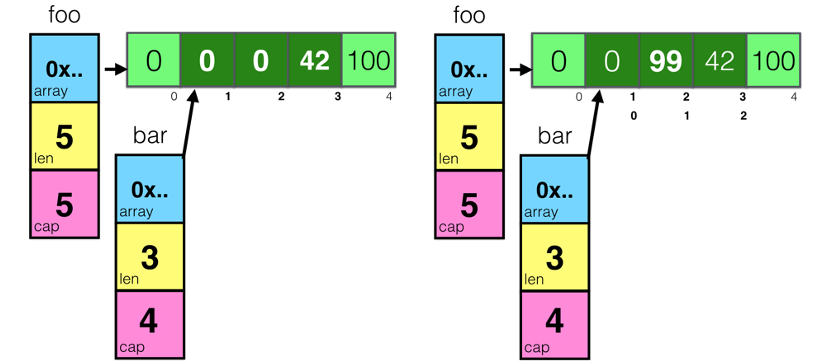
a := make([]int, 32)
b := a[1:16]
a = append(a, 1)
a[2] = 42
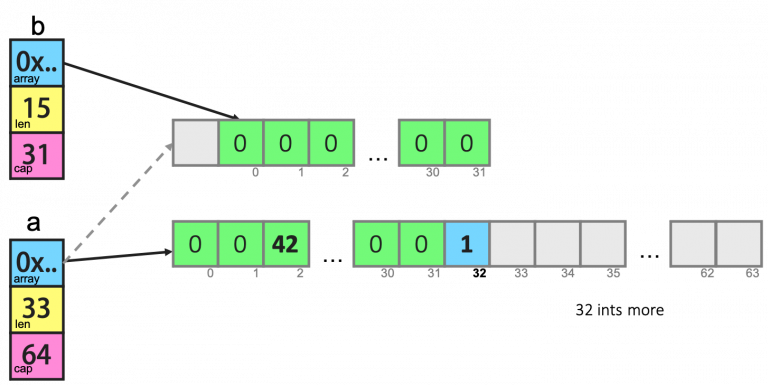
append()这个函数在cap不够用的时候就会重新分配内存以扩大容量,而如果够用的时候不会重新分配内存!
扩容规则:如果容量小于1024,则新容量为原来的2倍,如果容量大于1024,则新容量扩容为原来的1.25倍,再进行内存对齐操作。参考:
/src/runtime/slice.go:func growslice(et *_type, old slice, cap int) slice
func main() {
path := []byte("AAAA/BBBBBBBBB")
sepIndex := bytes.IndexByte(path, '/')
dir1 := path[:sepIndex]
dir2 := path[sepIndex+1:]
fmt.Println("dir1 =>", string(dir1)) //prints: dir1 => AAAA
fmt.Println("dir2 =>", string(dir2)) //prints: dir2 => BBBBBBBBB
dir1 = append(dir1, "suffix"...)
fmt.Println("dir1 =>", string(dir1)) //prints: dir1 => AAAAsuffix
fmt.Println("dir2 =>", string(dir2)) //prints: dir2 => uffixBBBB
fmt.Printf("0x%x, 0x%x", dir1, dir2)
}
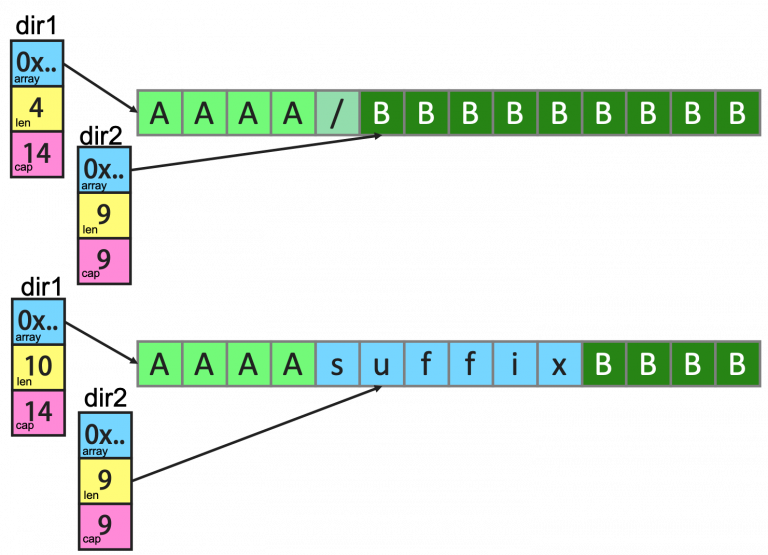
如果要解决这个问题,只需要将 dir1 := path[:sepIndex] 修改为 dir1 := path[:sepIndex:sepIndex],第三个参数sepIndex称为容量上界索引。
- 扩容时,底层数组怎么变化的
s1 := []int{1, 2}[:]
fmt.Printf("init slice slice addr=%p, len=%d, cap=%d, arr addr=0x%x\n", &s1, len(s1), cap(s1), (*reflect.SliceHeader)(unsafe.Pointer(&s1)).Data)
s1 = append(s1, 3)
fmt.Printf("after append 3, slice addr=%p, len=%d, cap=%d, arr addr=0x%x\n", &s1, len(s1), cap(s1), (*reflect.SliceHeader)(unsafe.Pointer(&s1)).Data)
s1 = append(s1, 4)
fmt.Printf("after append 4, slice addr=%p, len=%d, cap=%d, arr addr=0x%x\n", &s1, len(s1), cap(s1), (*reflect.SliceHeader)(unsafe.Pointer(&s1)).Data)
s1 = append(s1, 5)
fmt.Printf("after append 5, slice addr=%p, len=%d, cap=%d, arr addr=0x%x\n", &s1, len(s1), cap(s1), (*reflect.SliceHeader)(unsafe.Pointer(&s1)).Data)
// init slice slice addr=0xc000004078, len=2, cap=2, arr addr=0xc0000140a0
// after append 3, slice addr=0xc000004078, len=3, cap=4, arr addr=0xc0000102c0
// after append 4, slice addr=0xc000004078, len=4, cap=4, arr addr=0xc0000102c0
// after append 5, slice addr=0xc000004078, len=5, cap=8, arr addr=0xc00000c300
为什么用切片
Go 开发中通常优先使用切片,因为它高效、内存占用小
- 数组声明时需要指定数组大小;函数参数传递时,数组作为参数传递会有内存拷贝。
- 多个切片共用一个底层数组虽然能够减少内存占用,但是如果有一个切片修改内部的元素,其他切片也会受影响,所以在切片作为参数在函数间传递时要小心,尽可能不改变切片内的元素。
- 慎用append函数,append会改变切片底层数组
7、Map
- map声明格式
var map1 map[keytype]valuetype - 数组、切片、结构体,不能作为 key
- map 是无序的,不管按key还是value,都是无序的
- 禁止对map元素取址的原因是map可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
- 哈希表的每个桶最多只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会存储到哈希的溢出桶中。随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容(装载因子超过 6.5,元素数量/桶个数),扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
- 扩容:
- 装填因子是否大于6.5。装填因子 = 元素个数/桶个数
- overflow bucket是否太多:
- 当bucket的数量 < 2^15,但overflow bucket的数量大于桶数量
- 当bucket的数量 >= 2^15,但overflow bucket的数量大于2^15
- make初始化,对于不指定初始化大小,和初始化值hint<=8(bucketCnt,桶个数)时,go会调用makemap_small函数(源码位置src/runtime/map.go),并直接从堆上进行分配。
- 深入解析Golang的map设计
var mapempty map[string]int{}
var map0 map[string]int = map[string]int{}
map0["one"] = 1
var map1 map[string]int = map[string]int{"one": 1, "tow": 2}
map2 := map[string]int{"one": 1, "tow": 2}
map3 := make(map[string]int)
map3["one"] = 1
map3["two"] = 2
// 判断某个key是否在map中
if value, exist := map3["one"]; exist {
fmt.Println(value)
}
// 删除某个key
delete(map3, "one")
// 遍历map
for key, value := range map3 {
fmt.Println(key, value)
}
for key := range map3 {
fmt.Println(key, map3[key])
}